开发中常见的缓存算法 Lru算法
在软件开发中经常要用到缓存,如api网络请求结果缓存,图片加载缓存,本地操作记录缓存,比较常见的缓存算法就是Lru算法。
Lru(Least recently used)最近最少使用算法
根据算法命名字面意思我们大概了解到算法核心的逻辑是,最近最少使用的数据优先级最低 在缓存达到上限的时候优先会删除那些最近最少使用的数据。
那么怎么表示最近最少使用这个描述呢?
我最先想到的就是用一个时间数据来记录这个数据最后一次被使用的时间节点,每次使用这个数据就更新它最新的使用时间节点,当缓存达到上限的时候,删除那个时间节点最早的数据。
但是这个策略有一些明显的缺点
- 每个缓存数据条目多出一个时间记录数据,在空间使用上有多的消耗
- 每次达到缓存上限时,需遍历整个缓存的数据来比较出哪一个数据的时间是最早的 然后移除掉这个最早的数据。
看到这两个缺点 我们可以很快想到用一个有序容器去承载这些缓存数据,这个顺序就是这些缓存数据条目的最近使用时间节点前后的顺序,这样我们就可以解决这两个缺点了,不需要多出一个时间数据来记录,删除时直接删除这个有序容器中最后一个最早使用的数据即可了。
具体策略描述
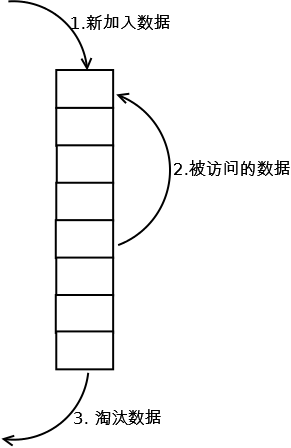
1.新加入的数据插入到顺序容器的头部;
2.每当缓存命中(即缓存数据被访问),则将数据移到顺序容器头部;
3.当容器满的时候,移除掉容器尾部的数据;
但是这个实现还是有缺点的
我们试想这样一种场景,当缓存容器中已经填满了缓存的数据,且最早使用的数据B也就是容器尾部的数据的使用频率也是很高,这时候先进来一个数据A,这个数据之前也没缓存中过,以后说不定也不会被使用,但是上面的这个实现策略是以时间节点为第一优先级的,那么此时这个新加的数据A就会替换掉一个使用频率还很高的数据B,如果这个数据A以后不会再用,那么这个数据A就是一个缓存污染数据,直到它被新的数据给挤掉。
那么有没有更好的解决方案呢?
也有就是新增一个频率描述数据或新增一个缓存容器,对于使用频率达到一定指标的数据会缓存到二级容器。同时这种算法会增加时间复杂度和空间复杂度,天下没有免费的午餐,干什么事都是需要代价的。
其他缓存替换策略
维基上面 Cache Replacement Policies 多达十多种,除了其中一些lru的变形版,主要还有下面这几种缓存替换策略:
- FIFO(first in first out) 先进先出策略(队列数据结构)
- 有点类似于lru,最早使用的优先被移除淘汰,但是跟lru不同的是 这个 “最早” 时间节点是这个数据第一次使用的时间节点,后面不管这个数据再次被使用几次,都不会更新时间节点,这就导致了就算数据A在命中最新一次使用,但是下次新来的数据B加入进来时,如果数据容器已满且数据A第一次使用的时间是最早的,位于容器队列的头部,那么它最先被移除。
- LIFO(last in first out) 后进先出策略(栈数据结构)
- MRU(most recently used) 最近最常使用
与lru正好相反,最近被使用的会被优先移除,你一定好奇为什么最近使用的反而会被最先移除?我们来看一些wiki的介绍:- Discards, in contrast to LRU, the most recently used items first. In findings presented at the 11th VLDB conference, Chou and DeWitt noted that “When a file is being repeatedly scanned in a [Looping Sequential] reference pattern, MRU is the best replacement algorithm.”[6] Subsequently other researchers presenting at the 22nd VLDB conference noted that for random access patterns and repeated scans over large datasets (sometimes known as cyclic access patterns) MRU cache algorithms have more hits than LRU due to their tendency to retain older data.[7] MRU algorithms are most useful in situations where the older an item is, the more likely it is to be accessed.
- 我们可以看出它的使用场景是 执行反复的文件扫描操作,只要满足了这样一个场景即是 最近被使用的数据 下一次被使用的概率很低 这样这个数据就不那么需要被缓存,优先级最低,最应该被替换 那么这种缓存算法无疑是最佳的
- Discards, in contrast to LRU, the most recently used items first. In findings presented at the 11th VLDB conference, Chou and DeWitt noted that “When a file is being repeatedly scanned in a [Looping Sequential] reference pattern, MRU is the best replacement algorithm.”[6] Subsequently other researchers presenting at the 22nd VLDB conference noted that for random access patterns and repeated scans over large datasets (sometimes known as cyclic access patterns) MRU cache algorithms have more hits than LRU due to their tendency to retain older data.[7] MRU algorithms are most useful in situations where the older an item is, the more likely it is to be accessed.
- LFU(Least Frequently Used) 最少使用次数
- 以使用次数为最高优先级 使用次数最少的被优先淘汰,即使是最近几次使用的数据
每种缓存策略都有它的适用场景,无所谓好坏。
Java中的LruCache
前面讲到lru缓存策略是以一个顺序容器来承载缓存数据,那么这个顺序容器在java中有哪些数据结构可以选择呢?
- 有序数组
- 优点 空间复杂度低,数组是一段连续的内存空间,内存资源使用效率高
- 缺点 时间复杂度高,新增,插入,删除,都需要对整个数据进行移位,效率较低
- 有序链表
- 优点 新增、删除时间复杂度较低,在头部和尾部对元素进行操作即可。
- 缺点 查找,插入时间复杂度较高,需遍历整个链表
- 有序map(LinkedHashMap、TreeMap)
- 优点 查找、新增、插入、删除时间复杂度低
- 缺点 空间复杂度高
LinkedHashMap
LinkedHashMap 继承于HashMap
与HashMap不同的是内部维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。如果我们选择迭代顺序是访问顺序,那不正好就满足了Lru算法的策略吗?
事实上 Java中一般就是使用LinkedHashMap来实现LruCache,例如Glide库中的LruCache,Okhttp中的DiskLruCache。
Glide中的LruCache:
public class LruCache<T, Y> {
private final LinkedHashMap<T, Y> cache = new LinkedHashMap<>(100, 0.75f, true);
private final int initialMaxSize;
private int maxSize;
private int currentSize = 0;
....
public synchronized Y put(T key, Y item) {
final int itemSize = getSize(item);
if (itemSize >= maxSize) {
onItemEvicted(key, item);
return null;
}
final Y result = cache.put(key, item);
if (item != null) {
currentSize += getSize(item);
}
if (result != null) {
// TODO: should we call onItemEvicted here?
currentSize -= getSize(result);
}
evict();
return result;
}
/**
* Removes the item at the given key and returns the removed item if present, and null otherwise.
*
* @param key The key to remove the item at.
*/
@Nullable
public synchronized Y remove(T key) {
final Y value = cache.remove(key);
if (value != null) {
currentSize -= getSize(value);
}
return value;
}
因为LinkedHashMap不是线程安全的,所以增加了synchronized关键字
那么LinkedHashMap的内部原理是怎样的呢?下面引入了极客学院关于linkedHashMap的原理分析的一段介绍
LinkedHashMap 的实现
对于 LinkedHashMap 而言,它继承与 HashMap(public class LinkedHashMap
成员变量LinkedHashMap 采用的 hash 算法和 HashMap 相同,但是它重新定义了数组中保存的元素 Entry,该 Entry 除了保存当前对象的引用外,还保存了其上一个元素 before 和下一个元素 after 的引用,从而在哈希表的基础上又构成了双向链接列表。看源代码:
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
* 如果为true,则按照访问顺序;如果为false,则按照插入顺序。
*/
private final boolean accessOrder;
/**
* 双向链表的表头元素。
*/
private transient Entry<K,V> header;
/**
* LinkedHashMap的Entry元素。
* 继承HashMap的Entry元素,又保存了其上一个元素before和下一个元素after的引用。
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
Entry<K,V> before, after;
……
}
LinkedHashMap 中的 Entry 集成与 HashMap 的 Entry,但是其增加了 before 和 after 的引用,指的是上一个元素和下一个元素的引用。
初始化
通过源代码可以看出,在 LinkedHashMap 的构造方法中,实际调用了父类 HashMap 的相关构造方法来构造一个底层存放的 table 数组,但额外可以增加 accessOrder 这个参数,如果不设置,默认为 false,代表按照插入顺序进行迭代;当然可以显式设置为 true,代表以访问顺序进行迭代。如:
public LinkedHashMap(int initialCapacity, float loadFactor,boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
我们已经知道 LinkedHashMap 的 Entry 元素继承 HashMap 的 Entry,提供了双向链表的功能。在上述 HashMap 的构造器中,最后会调用 init() 方法,进行相关的初始化,这个方法在 HashMap 的实现中并无意义,只是提供给子类实现相关的初始化调用。
但在 LinkedHashMap 重写了 init() 方法,在调用父类的构造方法完成构造后,进一步实现了对其元素 Entry 的初始化操作。
/**
* Called by superclass constructors and pseudoconstructors (clone,
* readObject) before any entries are inserted into the map. Initializes
* the chain.
*/
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
存储
LinkedHashMap 并未重写父类 HashMap 的 put 方法,而是重写了父类 HashMap 的 put 方法调用的子方法void recordAccess(HashMap m) ,void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的双向链接列表的实现。我们在之前的文章中已经讲解了HashMap的put方法,我们在这里重新贴一下 HashMap 的 put 方法的源代码:
HashMap.put:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
重写方法:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 调用create方法,将新元素以双向链表的的形式加入到映射中。
createEntry(hash, key, value, bucketIndex);
// 删除最近最少使用元素的策略定义
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
// 调用元素的addBrefore方法,将元素加入到哈希、双向链接列表。
e.addBefore(header);
size++;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
读取
LinkedHashMap 重写了父类 HashMap 的 get 方法,实际在调用父类 getEntry() 方法取得查找的元素后,再判断当排序模式 accessOrder 为 true 时,记录访问顺序,将最新访问的元素添加到双向链表的表头,并从原来的位置删除。由于的链表的增加、删除操作是常量级的,故并不会带来性能的损失。
public V get(Object key) {
// 调用父类HashMap的getEntry()方法,取得要查找的元素。
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 记录访问顺序。
e.recordAccess(this);
return e.value;
}
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
// 如果定义了LinkedHashMap的迭代顺序为访问顺序,
// 则删除以前位置上的元素,并将最新访问的元素添加到链表表头。
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
/**
* Removes this entry from the linked list.
*/
private void remove() {
before.after = after;
after.before = before;
}
/**clear链表,设置header为初始状态*/
public void clear() {
super.clear();
header.before = header.after = header;
}
最后
谢谢阅读!